谁说GPT只擅长生成?清华、智源等研究力证:GPT语言理解能力不输BERT
来源:机器之心Pro 2021-03-29 13:48:47
来源:机器之心
编辑:张倩、小舟
一直以来,GPT模型的语言生成能力有目共睹,但语言理解能力似乎略逊一筹。最近,清华、智源等机构的一项研究打破了这一刻板印象。GPT-3 大型语言模型向我们展示了 AI 模型在生成自然语言文本方面的强大能力。从创作历史人物对话到总结电影再到编写代码,GPT-3 似乎无所不能。
然而,尽管 GPT-3 的输出在语法上是正确的,甚至在习惯用法上也令人印象深刻,但它对语言的理解似乎存在明显不足,以至于一些生成效果令人大跌眼镜。例如:
问:铅笔和烤面包机哪个更重?
答:铅笔比烤面包机重。
GPT-3 的成功表明,「巨大的单向语言模型 + 适当的手工 prompt」这一组合可能有助于提高模型的自然语言理解能力。然而,手工制作表现最佳的 prompt 无异于大海捞针,通常需要异常庞大的验证集。在很多情况下,有效的 prompt 工程意味着过拟合测试集。而且,这很容易导致对抗 prompt 的产生,进而导致模型性能大幅下降。
为了解决这些问题,部分研究者致力于自动搜索离散 prompt 并取得了一些成效,但神经网络本质上是连续的,因此离散 prompt 可能并非最优。
在一篇标题为《GPT Understands, Too》的论文中,来自清华大学、麻省理工、北京智源人工智能研究院、Recurrent AI 的 Xiao Liu、唐杰、杨植麟等研究者提出了一种名为 P-tuning 的新方法来自动搜索连续空间中的 prompt,以提高 GPT 模型的自然语言理解能力。

论文链接:https://arxiv.org/pdf/2103.10385.pdf
项目链接:https://github.com/THUDM/P-tuning
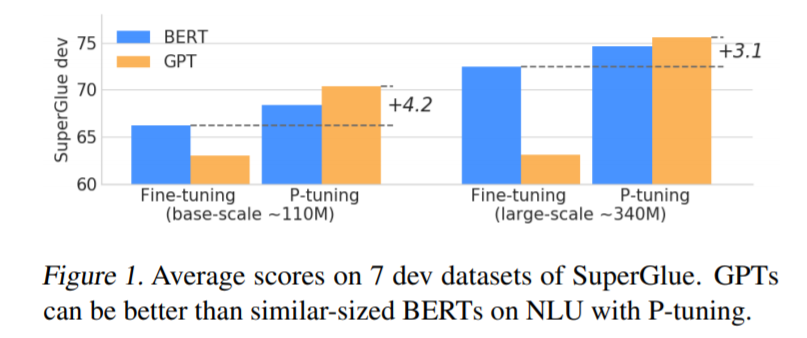
实验结果表明,利用 P-tuning 方法,GPT 的自然语言能力可以匹敌 BERT。而且,P-tuning 还可以提高 BERT 在 few-shot 和监督场景下的性能。
该研究的主要贡献如下:
1. 表明在 P-tuning 的加持下,GPT 也能拥有和 BERT 一样强大(有时甚至超越后者)的自然语言理解能力,而 P-tuning 可以提高预训练语言模型的性能。这表明,GPT 类架构在自然语言理解方面的能力被低估了。
2. 表明 P-tuning 是一种提高 GPT 和 BERT 在 few-shot 和全监督场景中自然语言理解能力的通用方法。在 LAMA knowledge probing 和 few-shot SuperGLUE 两个基准的测试中,该方法优于之前的 SOTA 方法,表明语言模型在预训练过程中掌握的世界知识和 prior-task 知识比以往认为的要多。
同时,这一新方法也是北京智源人工智能研究院前段时间发布的超大规模智能模型——「悟道 1.0」的一部分。「悟道 1.0」是我国首个超大规模智能模型系统,由智源研究院学术副院长、清华大学唐杰教授领衔,带领来自北京大学、清华大学、中国人民大学、中国科学院等单位的 100 余位 AI 科学家团队联合攻关,取得了多项国际领先的 AI 技术突破,形成超大规模智能模型训练技术体系,训练出包括中文、多模态、认知、蛋白质预测在内的系列模型,勇闯通用智能发展前沿,构建我国人工智能应用基础设施。

「悟道 1.0」先期启动了 4 个大模型的研发,分别是面向中文的预训练语言模型「悟道 · 文源」、首个公开的中文通用图文多模态预训练模型「悟道 · 文澜」、我国首个具有认知能力的超大规模预训练模型「悟道 · 文汇」和超大规模蛋白质序列预测预训练模型「悟道 · 文溯」。P-Tuning 属于「悟道 · 文汇」,使得自回归模型在理解任务上首次超越自编码模型,还在知识抽取 (LAMA)、少样本学习 (Superglue Fewshot) 等 10 多个任务上取得世界第一,性能提升超 20%。
P-tuning:自动搜索连续空间中的 prompt
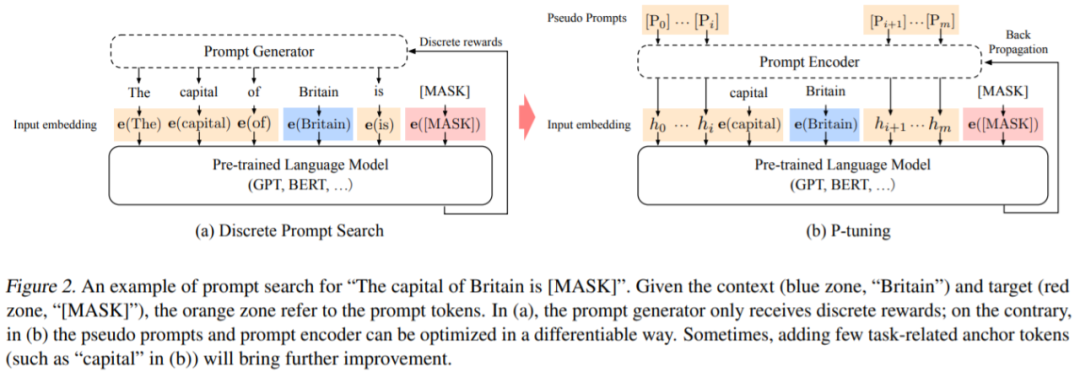
P-tuning 架构本身比较简单。给定一个预训练的语言模型,通过预训练的嵌入层将一组离散输入 token 映射到输入嵌入。prompt p 的作用是将上下文 x、目标 y 和自身组合成一个 template t。借助这种方式,该方法可以找到更好的连续 prompt,并通过下游损失函数对连续 prompt 进行优化。
架构细节
给定一个预训练的语言模型 M,离散输入 token 序列「x_1:n = {x_0, x_1, ..., x_n}」将被预训练嵌入层 e ∈ M 映射到输入嵌入 {e(x_0), e(x_1), ..., e(x_n)} 。在以上下文 x 为条件的特定场景中,我们经常使用一组目标 token「y」的输出嵌入来进行下游处理。例如,在预训练中,x 为 unmasked token,y 为 [MASK] token;在句子分类中,x 为句子 token,y 通常指 [CLS]。
prompt p 的作用是将上下文 x、目标 y 和自身组合成一个 template t。例如,在一个预测国家首都的任务中(LAMA-TREx P36),「The capital of Britain is [MASK]」就是一个 template(如图 2 所示)。其中,「The capital of ... is ....」就是 prompt,「Britain」就是上下文,而「[MASK]」就是目标。Prompt 非常灵活,我们甚至可以将其插入上下文或目标。
设 V 为语言模型 M 的词汇表, [P_i] 为 template T 中的第 i 个 prompt token。为简单起见,给定一个 template
 ,传统离散 prompt 满足 [P_i ] ∈ V 并将 T 映射到
,传统离散 prompt 满足 [P_i ] ∈ V 并将 T 映射到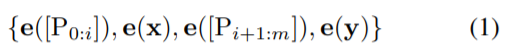
P-tuning 并非如此。它将 [P_i] 视为伪 token,并将 template 映射到:
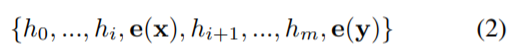
其中,h_i(0 ≤ i < m) 是可训练的嵌入张量。这使得我们能够在 V 所能表达的原有词汇之外找到更好的连续 prompt。最后,利用下游损失函数 L,对连续 prompt h_i(0 ≤ i < m) 进行优化
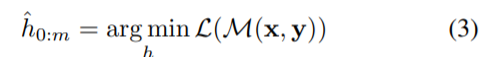
实验
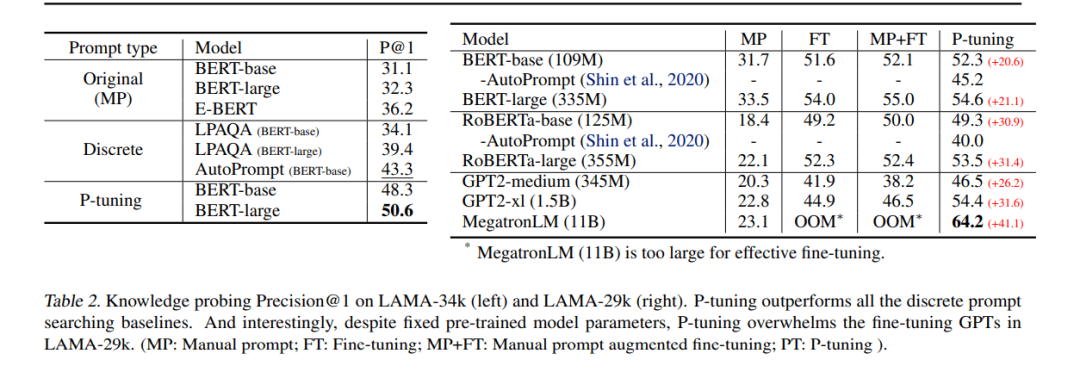
研究团队在流行的 LAMA knowledge probing 和 SuperGLUE NLU 基准上对模型进行了测试。
其中,LAMA knowledge probing 用来评估语言模型从预训练中得到了多少知识。实验结果显示,P-tuning 极大地提高了模型的 knowledge-probing 性能。这表明,仅仅是找到一个更好的 prompt(不需要微调),我们就能让语言模型获得更多的知识。P-tuning 也可以超越之前的 AutoPrompt、LPAQA 等离散 prompt 搜索方法。
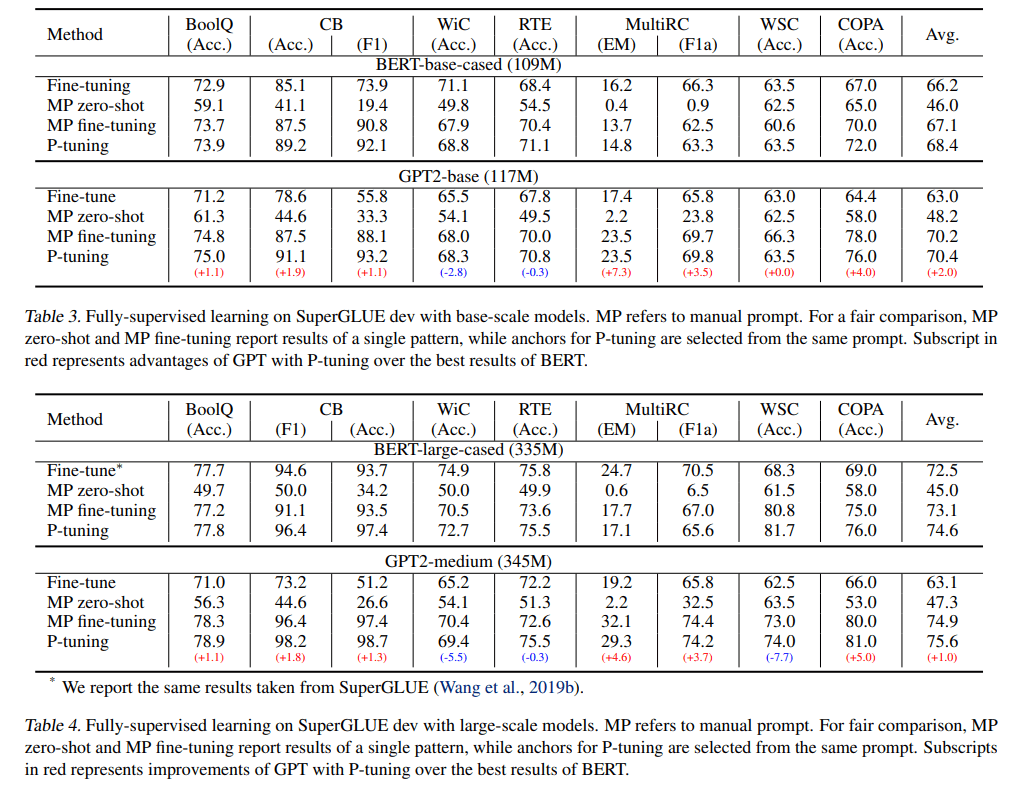
在 SuperGLUE 的测试中,研究人员考虑了全监督和 few-shot 两种设置,任务包括问答(BoolQ 和 MultiRC)、文本蕴涵(CB 和 RTE)、指代消解(WiC)、因果推理(COPA)和词义消歧(WSC)。
在全监督设置下,对于 BERT-base-cased 和 BERT-large-cased 模型,P-tuning 方法在大多数任务中都超越了其他所有 BERT-based 模型。此外,P-tuning 在 GPT-2-base 和 GPT-2-medium 模型上也取得了令人惊喜的结果。
代替手工prompt
GPT-3 这样的大模型可移植性往往较差,这意味着,对这些模型进行微调以适应下游任务的做法并不可行。因此,GPT-3 利用手工 prompt 提高模型在下游任务中的可用性。然而,这些手工 prompt 搜索严重依赖不现实的大型验证集,改动其中的一个词就可能导致性能的严重下降。

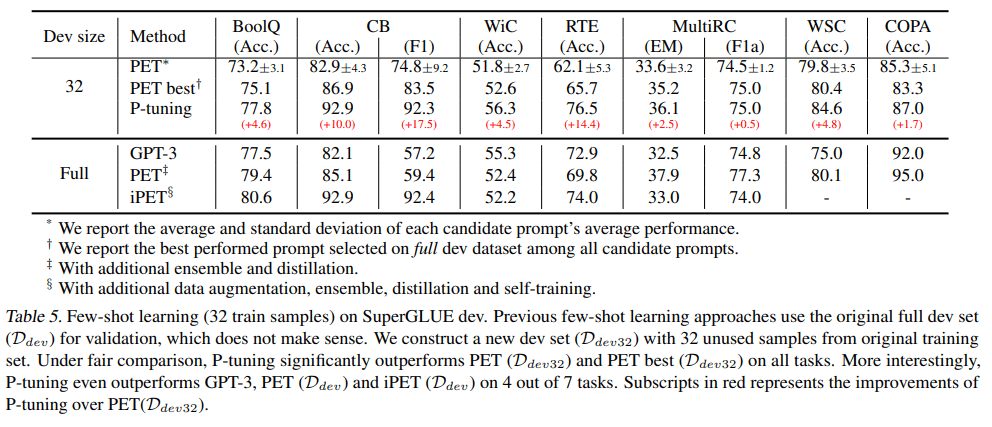
下表给出了使用手工 prompt 和 P-tuning 的对比结果。如表中数据所示,使用 D_dev32 找到性能最佳的手工 prompt 并不现实,在 few-shot 设置中挑选出最佳的手工 prompt 是一项极具挑战性的任务。相比之下,使用 P-tuning 自动搜索 prompt 的方法更具优势。

在 few-shot 学习设置下,P-tuning 在所有的任务中都超越了带有手工 prompt 的 PET (D_dev32) 和 PET-best (D_dev32) 方法。与 GPT-3 相比,P-tuning 在六项任务(共七项)中都提高了模型的自然语言理解性能,证明与手工方法相比,P-tuning 可以搜索出好得多的 prompt,同时大幅提升模型在 few-shot 任务中的性能。
参考链接:https://www.iheima.com/article-313904.html
亚马逊云科技线上黑客松2021
这是一场志同道合的磨练,这是一场高手云集的组团竞技。秀脑洞、玩创意,3月26日至5月31日,实战的舞台为你开启,「亚马逊云科技线上黑客松2021」等你来战!
为了鼓励开发者的参与和创新,本次大赛为参赛者准备了丰厚的奖品,在一、二、三等奖之外,还特设prActIcal奖、creAtIve奖、锦鲤极客奖、阳光普照奖,成功提交作品的团队均可获赠奖品。

©THEEND
转载请联系本公众号获得授权
相关文章



猜你喜欢
今日头条
图文推荐






精彩文章
