AAAI 2022 | 无注意力+PatchOut,复旦大学提出面向视觉transformer的迁移攻击方法
来源:机器之心Pro 2021-12-28 14:45:25
机器之心专栏
作者:复旦大学以人为本人工智能研究中心
本文中,来自复旦大学以人为本人工智能研究中心和马里兰大学的研究者提出了一种双重攻击框架,以提高不同 ViT 模型之间,甚至 ViT 与 CNN 之间对抗样本的迁移性。
与卷积神经网络(CNN)相比,Vision transformers(ViTs)在一系列计算机视觉任务中表现出惊人的性能。然而,ViTs 容易受到来自对抗样本的攻击。在人的视角中,对抗样本与干净样本几乎没有区别,但其包含可以导致错误预测的对抗噪声。此外,对抗样本的迁移性允许在可完全访问的模型(白盒模型)上生成对抗样本来攻击结构等信息未知的模型(黑盒模型)。
目前,对抗样本的迁移性在 CNNs 中得到了较为详尽的研究。这些工作利用数据增强或更优的梯度计算来防止对抗样本过拟合白盒模型,以此提高针对黑盒模型的攻击成功率。但关于 ViTs 中对抗样本迁移性的研究较少,且由于 CNNs 和 ViTs 间结构存在较大差异,在 CNNs 中表现良好的方法很难迁移到 ViTs 中来。
针对 ViTs 结构中的图像块(patch)输入和多头自注意力(Multi-headed Self-Attention,MSA)模块,来自复旦大学以人为本人工智能研究中心和马里兰大学的研究人员提出了双重攻击框架,包含无注意力(Pay No Attention,PNA)攻击和 PatchOut 攻击,来提高不同 ViT 模型之间甚至 ViT 与 CNN 之间对抗样本的迁移性。研究论文已被 AAAI 2022 接收。

论文链接:https://arxiv.org/pdf/2109.04176.pdf
代码链接:https://github.com/zhipeng-wei/PNA-PatchOut
无注意力攻击
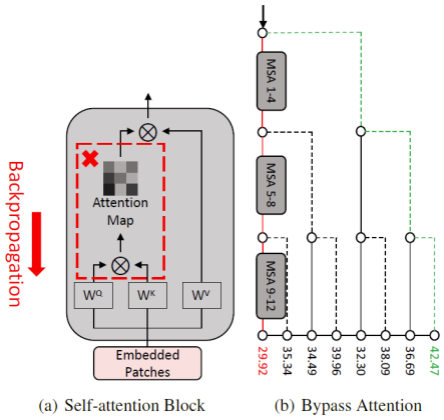
ViTs 中的 MSA 模块通过映射来自多头的拼接输出,整合来自不同表示子空间的信息。而研究人员发现在梯度反向传播过程中跳过注意力路径(如下图(a)所示),可以有效提升对抗样本的迁移性。为了验证这一假设,研究人员将 ViT-B/16 模型中的 12 层 MSA 模块划分为 3 个部分:MSA 1-4,MSA 5-8 和 MSA 9-12。通过包含或删除每一部分的注意力路径,可获得 8 条不同的梯度反向传播路径。
这里使用 BIM(Basic Iterative Method)方法沿着 8 条不同梯度反向传播路径生成对抗样本,并评估在其他黑盒 ViTs 模型上的攻击成功率。该结果如下图(b)所示,红色路径表示梯度反向传播路径经过所有 MSA 模块,绿色路径表示跳过所有 MSA 模块中的注意力路径。结果显示通过在梯度反向传播中跳过注意力路径可以将迁移攻击成功率由 29.92% 提高至 42.47%。
PNA 攻击允许每个 patch 关注自身,而不是依赖于复杂的 patch 间的相互作用。而在 Interaction-Reduced(IR)攻击中表明对抗迁移性与 patch 间的相互作用负相关。因此,PNA 攻击可降低 patch 间相互作用,从而提升对抗迁移性。这是 PNA 可提升对抗迁移性的一个原因。
 PNA 攻击的示意图和验证性实验
PNA 攻击的示意图和验证性实验使用
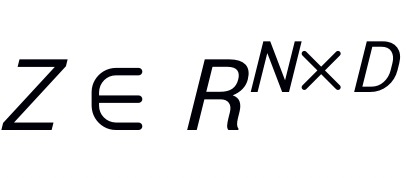 表示输入的 patch embedding,其中N为 patch 的数目,D为 patch 的特征大小;使用
表示输入的 patch embedding,其中N为 patch 的数目,D为 patch 的特征大小;使用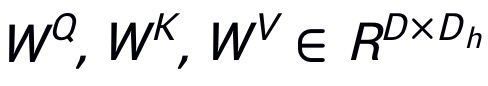 分别表示 query、key 和 value 的权重,那么注意力图可以表示为:
分别表示 query、key 和 value 的权重,那么注意力图可以表示为: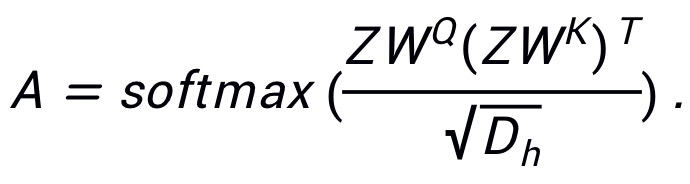
得到的注意力图
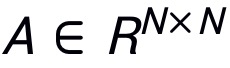
,那么该 MSA 模块的输出则为:

此时,Z'关于输入Z的梯度信息可以表示为:
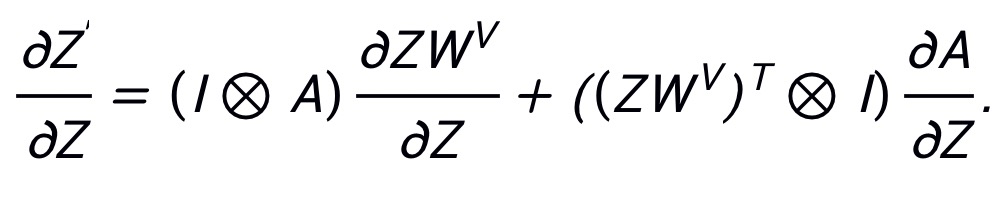
其中
 表示 Kronecker 积。由于 PNA 攻击在梯度反向传播过程中跳过了注意力路径,则
表示 Kronecker 积。由于 PNA 攻击在梯度反向传播过程中跳过了注意力路径,则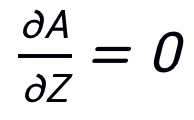 ,那么梯度信息将变为:
,那么梯度信息将变为: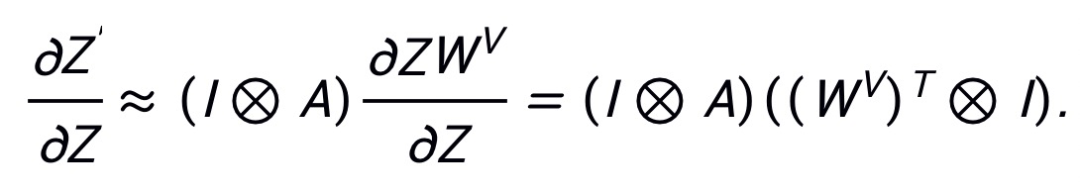
通过以上方式,PNA 攻击强迫白盒 ViTs 模型不利用高度模型特异的注意力信息,而挖掘 patch 自身的特征表达,以此生成具有高迁移性的对抗样本。
PatchOut 攻击
ViTs 将输入图像划分为多个 patch 来作为输入。根据这一特性,PatchOut 攻击在每次迭代攻击中随机选择部分 patch 来生成对抗样本。该操作类似于在 patch 中执行 dropout 操作来减轻过拟合。此外,还类似于 Diversity Input(DI)攻击,采取多样性的输入来提升对抗样本的迁移性。为了验证 PatchOut 的有效性,研究人员随机选择 10 个 patch 作为一个输入模式,称之为 “ten-patches”。下图展示了不同 ten-patches 数目下单独优化和整体优化对于迁移攻击成功率的影响。可以看出,叠加单独优化的 ten-patches 噪声比整体优化的相同的 ten-patches 噪声具有更高的迁移性。这一结果说明通过叠加来自不同输入模式的噪声可以提高对抗样本的迁移性。
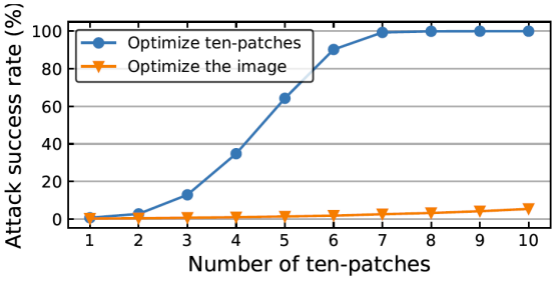
不同 ten-patches 数目下的攻击成功率对比
由于迭代攻击次数的限制,PatchOut 攻击选择在每次迭代中随机选取部分 patch 来生成对抗噪声。这里,使用
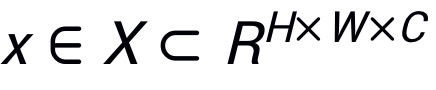 表示输入图像,
表示输入图像,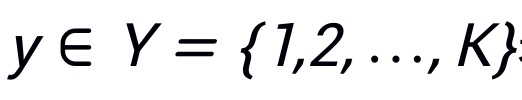 表示其对应真实标签,其中H,W,C分别表示图像的高度,宽度和通道数,K表示类别数目。使用
表示其对应真实标签,其中H,W,C分别表示图像的高度,宽度和通道数,K表示类别数目。使用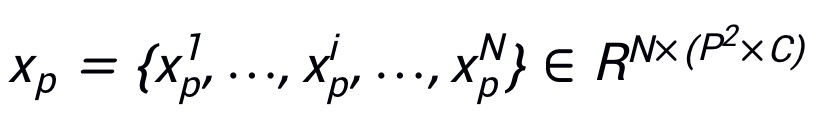 表示 patch,其中表示x的第i个 patch,(P,P)表示的分辨率,
表示 patch,其中表示x的第i个 patch,(P,P)表示的分辨率,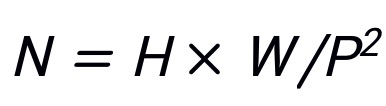 为 patch 的数目。使用
为 patch 的数目。使用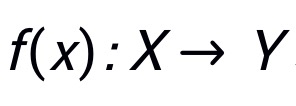 表示模型对于输入的预测结果。定义为对抗噪声,那么攻击目标可以定义为
表示模型对于输入的预测结果。定义为对抗噪声,那么攻击目标可以定义为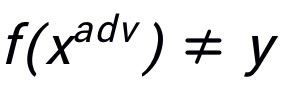 ,其中
,其中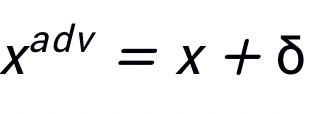 ,且限制
,且限制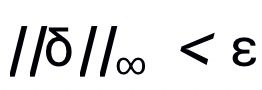 。定义
。定义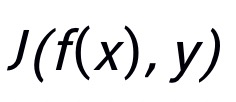 为损失函数。使用来控制在每次迭代中 patch 的数目,并且使用
为损失函数。使用来控制在每次迭代中 patch 的数目,并且使用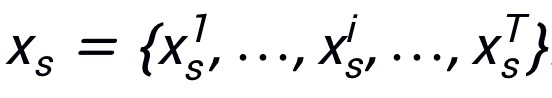 来表示选择到的 patch。那么攻击掩码
来表示选择到的 patch。那么攻击掩码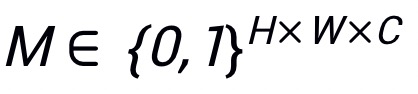 可定义为:
可定义为: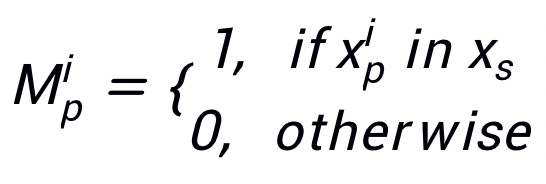
其中
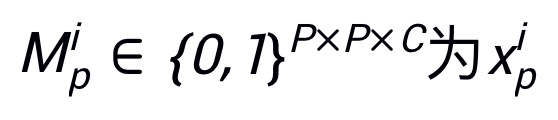 为所对应的掩码。结合最大化 L2 距离后,PatchOut 攻击的目标函数可以定义为:
为所对应的掩码。结合最大化 L2 距离后,PatchOut 攻击的目标函数可以定义为: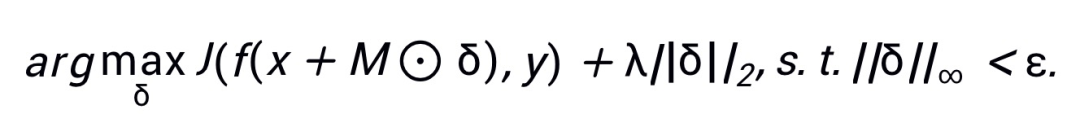
其中
表示逐元素相乘,损失中的第二项鼓励对抗样本远离x,λ为控制 L2 项和损失项间平衡的超参数。
双重攻击框架的整体算法如下,其中
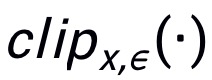 用来限制生成的对抗噪声满足
用来限制生成的对抗噪声满足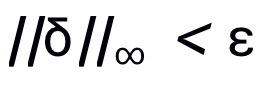
。

结果讨论与分析
为了探究 PNA 和 PatchOut 攻击的性能,研究人员在 ImageNet 数据集上,针对 8 个 ViTs 模型:ViT-B/16、DeiT-B、TNT-S、LeViT-256、PiT-B、CaiT-S-24、ConViT-B、和 Visformer-S,4 个 CNNs 模型:Inception v3、Inception v4、Inception Resnet v2 和 Resnet v2-152,3 个经过对抗训练的 CNNs 模型:Inception v3_ens3、Inception v3_ens4、Inception Resnet v2_ens 进行实验。其中,分别选取 ViT-B/16、PiT-B、CaiT-S-24、Visformer-S 作为白盒模型来生成对抗样本,使用剩余的模型作为黑盒模型,并计算攻击成功率(Attack Success Rate,ASR)来评估对抗样本的迁移性。
研究人员首先在不同的 ViTs 中评估了双重攻击框架的性能,如下表所示。首先 TI 和 ATA 作为在 CNNs 上有效的迁移性方法,却在 ViTs 中表现不佳。这是由于 ViTs 的模型结构具有较 CNNs 更少的图像特异的归纳偏差。其次,受限于类别词元(class tokens)的数目,专门为 ViTs 设计的 SE 方法的性能也较差。而研究人员提出的双重攻击方法取得了最好的性能,可平均达到 58.67% ASR。该实验结果验证了所提出双重攻击框架在不同 ViTs 模型间的有效性。
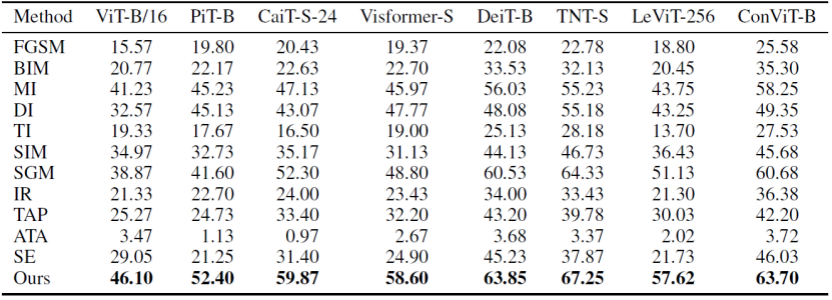
不同攻击方法在 ViTs 上的攻击成功率结果对比
研究人员进一步利用 ViTs 上生成的对抗样本攻击 CNNs 模型,其结果如下表所示。首先,所有方法的 ASR 发生了显著地下降,这意味着对抗样本在同结构模型中更易迁移。其次,与其他方法相比,所提出的双重攻击框架仍旧实现了更好的性能。该结果表示使用 ViTs 来攻击经过对抗训练的 CNNs 是可行的。
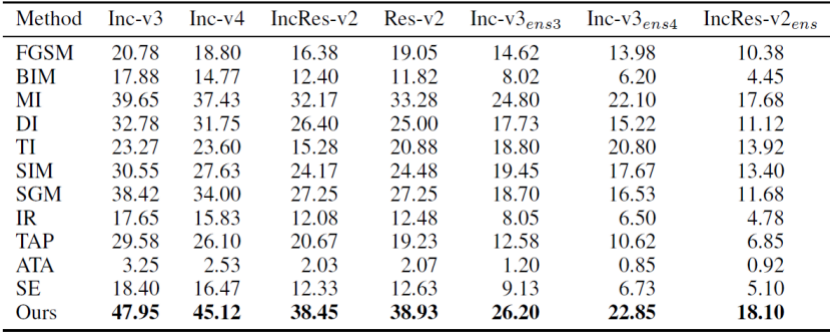
不同攻击方法在 CNNs 上的攻击成功率结果对比
所提出的双重攻击框架还可以与其他现有方法相结合,以进一步提升对抗样本的迁移性。其结果如下表所示。可以看出,结合现有方法后可在 ViTs,CNNs 和经过对抗训练的 CNNs 上都取得更好的性能。结果证明了双重攻击方法的易拓展性。
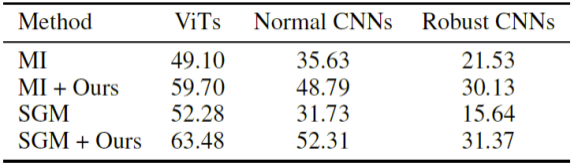
结合现有方法的平均 ASR 结果对比
此外,研究人员还针对双重攻击框架中的多个组件进行了消融实验,如下表所示。可以看到,任何一个组件都可以在 ViTs 和 CNNs 上带来性能提升,其中 PNA 攻击方法提升最明显。且当组合三个组件时达到了最佳结果,表明三个组件以互补的方式提高了对抗样本的迁移性。
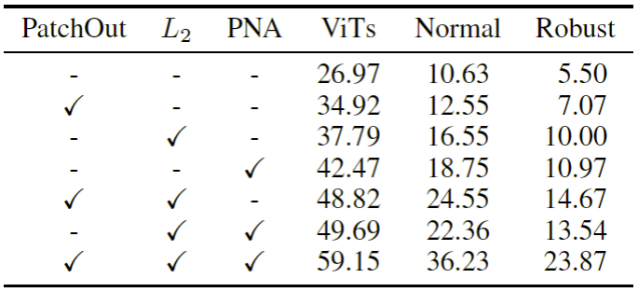
不同组件的性能对比结果
研究人员还对使用 patch 的数目T和超参数λ进行了调节。当T=N时,PatchOut 方法退化为 BIM 方法。而当T过于小时,PatchOut 无法在有限的迭代次数里生成更强的对抗样本,因此对于参数T取值的研究是十分有必要的。下图(a)展示了不同T的 ASR,可以看出当T=130时,PatchOut 攻击可取得最优的结果。此外,图(b)对不同取值的超参数进行了研究。当λ=0.1时,PatchOut 取得最好的结果。
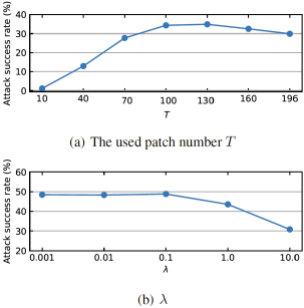
使用不同(a)或(b)下 ASR 的变化情况
相关文章




猜你喜欢
今日头条
图文推荐






精彩文章

随机推荐